안녕하세요, 저는 당근페이 인프라팀에서 Site Reliability Engineer로 일하고 있는 Yany라고 해요. 저희 팀은 당근페이의 인프라를 안정적으로 관리해요. 개발자들의 프로덕트 개발 속도를 향상하고, 동시에 비용도 최적화하죠.
저희는 클러스터 오토스케일링 없이 ASG(AWS EC2 AutoScaling Group)로, 그리고 HorizontalPodAutoscaler 없이 클러스터를 관리하고 있었어요. 여기에는 몇 가지 문제가 있었어요:
- 스케일 아웃 과정에서 네트워크에 여러 병목 지점이 생겼어요.
- 클러스터 업데이트를 진행하면서 ASG마다 AMI를 업데이트해야 했고, 오토스케일링이 원활하지 못했어요.
- 컴플라이언스 이슈로 인해 분리된 노드, 서브넷에서 동작해야 하는 워크로드가 증가하면서 ASG가 늘어나 관리 포인트가 증가하고 있었어요.
- 새벽 시간대에 트래픽이 현저히 적은 것에 비해 리소스를 너무 많이 사용하고 있었어요.
당근페이의 거래량과 유저 수가 급격히 증가하면서, 기존의 ASG 기반 인프라 운영 방식으로는 한계가 명확해졌어요. 이에 따라 더 유연하고 자동화된 클러스터 스케일링이 필요했고, 그 해답으로 Karpenter를 도입하게 되었어요.
그 여정은 저희가 생각한 것만큼 마냥 쉽지만은 않았는데요. 이번 글에서는 그 트러블슈팅 과정을 구체적으로 소개해드리려고 해요. Karpenter 도입을 고민 중이시거나 더 효율적으로 사용할 방법을 찾고 계신다면, 이 글이 큰 도움이 되길 바라요.
Karpenter란?
Karpenter는 쿠버네티스 클러스터에서 파드의 수요에 맞춰 노드의 양을 조절하는 Cluster Autoscaling Operator에요. 여러 컴포넌트를 통해 원하는 규격의 노드를 생성하고, 생성된 노드의 생명주기를 관리하도록 도와줘요.

대표적인 기능은 아래와 같아요:
Provisioning
- Pending 상태의 파드가 존재하면, 스케줄링을 통해 필요한 노드를 생성하여 해당 파드가 스케줄링될 수 있도록 해요.
- 각 CSP(Cloud Service Provider, 저희의 경우 AWS가 여기에 해당해요.)에서 만든 NodeClass 구현체를 통해 인스턴스의 규격을 정해요.
- AWS로 가정했을 때 AMI, Subnet, Storage, Security Group, Userdata 등 EC2 인스턴스 자체와 관련된 설정을 진행할 수 있어요. - NodePool을 통해 기존 ASG처럼 목적별로 노드를 생성할 수 있어요.
- 여러 타입의 인스턴스를 생성할 수 있어, Cluster Autoscaler (이하 CA)보다 훨씬 효율적으로 스케일링을 진행할 수 있어요.
Disruption
- Drift: NodeClass, NodePool이 바뀌면 Drift를 통해 노드들을 원하는 상태로 Sync할 수 있어요.
- Consolidation: 충분히 사용하고 있지 않은 노드를 삭제해서 최적화된 양의 리소스를 사용할 수 있어요.
-SingleNodeConsolidation: 활용도가 낮은 개별 노드를 식별해요. 해당 노드의 워크로드를 다른 노드로 이동한 후 불필요한 노드를 삭제함으로써 리소스 낭비를 줄여요.
-MultiNodeConsolidation: 여러 개의 작은 노드에 분산된 워크로드를 더 적은 수의 큰 노드로 통합하여 리소스 효율성을 높여요. 이 과정에서 Karpenter는 기존 노드들을 대체할 수 있는 최적의 노드 구성을 자동으로 계산해요.
-EmptyNodeConsolidation: 워크로드가 전혀 실행되지 않는 빈 노드를 감지하여 신속하게 삭제함으로써 불필요한 리소스 비용을 절감해요. 이는 클러스터에서 사용되지 않는 자원을 즉시 회수하는 데 효과적이에요. - Expiration: 노드의 수명을 정하고, 그 시간이 지나면 노드를 삭제해요.
주요 컴포넌트는 NodeClass (AWS 구현체의 경우 EC2NodeClass, Azure 구현체의 경우 AKSNodeClass)NodePool, NodeClaim이 있어요. 각 역할은 다음과 같아요:

Karpenter와 CA의 특징을 항목별로 비교해 보면 아래와 같아요:

Karpenter는 확실히 CA보다 더 효율적이고 빠른 오토스케일링이 가능하도록 지원해 준다는 점에서 커뮤니티에서 인기가 많아요. 저희도 그런 이유로 도입했고요. 하지만 다양한 측면에서 예상하지 못했던 문제점들을 마주했는데요. 어떤 문제들을 마주했고 어떻게 해결했는지 본격적으로 설명해 드릴게요.
Troubleshooting
1. 스케줄링이 생각처럼 되지 않아요
처음 Karpenter를 PoC할 땐 대체로 잘 확장됐었지만, 때때로 한두 개의 파드들이 Pending 상태에서 풀리지 않고 대기하는 것을 발견했어요. 이 부분을 해결하기 위해 스케줄링 로직을 더 파보면서 재밌는 사실을 알게 되었어요. 바로 Karpenter 내부에서 스케줄링을 시뮬레이션한다는 사실이었어요.
Karpenter의 스케줄링은 아래와 같은 상황에서 발생하게 돼요:
ProvisioningLoop가 돌 때
클러스터 내에서 파드가Pending되는 이벤트를 탐지해요. 이런 Loop를 끊임없이 반복해서 지속적으로 클러스터 리소스들을 탐색하는 과정을 거쳐요. 파드의 수요가 실제 리소스를 넘는 순간을 빠르게 포착한 후 얼마나 리소스가 더 필요한지 계산해야 하기 때문에 스케줄링이 필요해요.DisruptionLoop가 돌 때 (Consolidation,Draft등)Disruption또한ProvisioningLoop와 마찬가지로 끊임없이 반복하는데요. 현재 노드가 파드 수요보다 많아 불필요하게 사용되는 리소스를 탐지해요. 특정 노드를 지운 후의 파드 스케줄링 방법, 새로운 노드의 생성 여부를 결정해야 하기 때문에 스케줄링이 필요해요.
스케줄링 동작 방식
우선 스케줄링 대상 파드를 선정하기부터 큐에서 파드 하나를 추출하기까지의 과정을 도식으로 나타내면 아래와 같은데요. 단계별로 각 과정을 설명할게요.
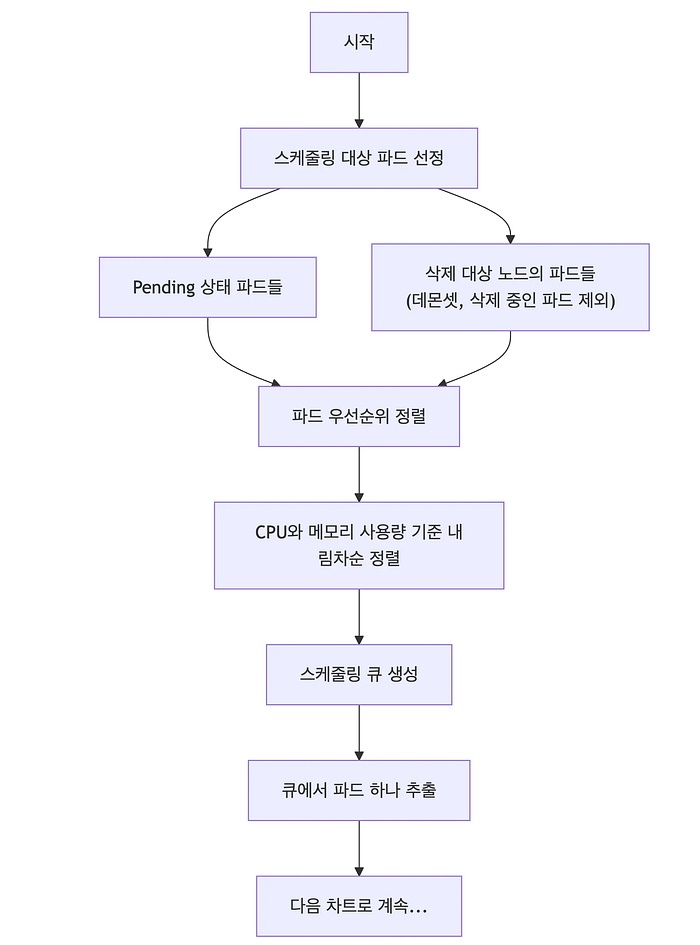
먼저 파드들은 아래의 조건에 부합해야 스케줄링 대상으로 선정돼요.
Pending상태의 파드들- 삭제 대상인 노드의 파드 중
DaemonSet과 이미 삭제되고 있는 파드들
- 노드status의MarkedForDeletion이true인지
- 노드 자체가NodeClaim과 관계없이 삭제되고 있는지
-NodeClaim, 혹은 매핑된 노드가 삭제되고 있는지
이렇게 스케줄링 대상 파드들을 정리했으면, 먼저 CPU와 메모리를 많이 사용하는 순서대로 정렬해요. 그 후 큐로 만들어서 리소스를 많이 사용하는 파드들부터 순차적으로 스케줄링을 시작해요.
func byCPUAndMemoryDescending(pods []*v1.Pod, podRequests map[types.UID]v1.ResourceList) func(i int, j int) bool {
return func(i, j int) bool {
lhsPod := pods[i]
rhsPod := pods[j]
lhs := podRequests[lhsPod.UID]
rhs := podRequests[rhsPod.UID]
cpuCmp := resources.Cmp(lhs[v1.ResourceCPU], rhs[v1.ResourceCPU])
if cpuCmp < 0 {
return false
} else if cpuCmp > 0 {
return true
}
memCmp := resources.Cmp(lhs[v1.ResourceMemory], rhs[v1.ResourceMemory])
if memCmp < 0 {
return false
} else if memCmp > 0 {
return true
}
return lhsPod.UID < rhsPod.UID
}
}위 과정을 마쳤다면 이제 본격적으로 스케줄링을 시도할 수 있는데요. 이후의 과정을 도식으로 나타나면 아래와 같아요.
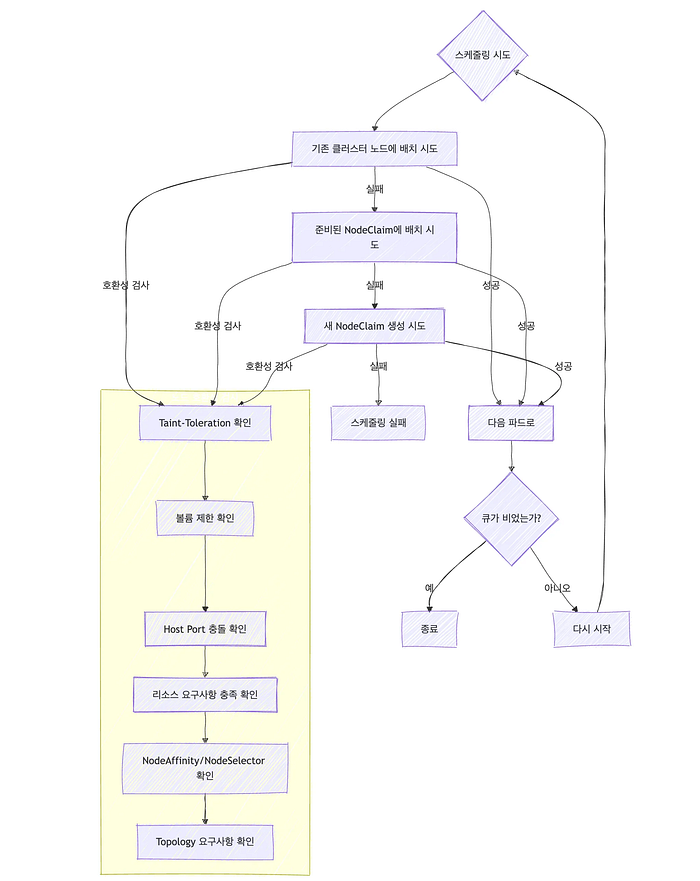
가장 먼저 큐에서 파드들을 하나씩 꺼내서 노드에 배치하기 시작하는데, 여기서 기본적인 kube-scheduler의 동작을 모방하기 시작해요. (소스코드)
파드를 배치하고자 하는 노드에는 아래와 같은 우선순위로 작업이 진행돼요.
- 클러스터 내 실제 노드에서 먼저 스케줄링 시도
// 클러스터 내 실제 노드에서 먼저 스케줄링을 시도해요.
for _, node := range s.existingNodes {
if err := node.Add(ctx, s.kubeClient, pod, s.cachedPodData[pod.UID]); err == nil {
return nil
}
}2. 생성하려고 준비한 NodeClaim에 스케줄링 시도
// Consider using https://pkg.go.dev/container/heap
sort.Slice(s.newNodeClaims, func(a, b int) bool { return len(s.newNodeClaims[a].Pods) < len(s.newNodeClaims[b].Pods) })
// 생성하려고 준비한 NodeClaim에도 스케줄링을 시도해요.
for _, nodeClaim := range s.newNodeClaims {
if err := nodeClaim.Add(pod, s.cachedPodData[pod.UID]); err == nil {
return nil
}
}3. 새로운 NodeClaim 생성
// 노드를 새로 생성해요.
var errs error
for _, nodeClaimTemplate := range s.nodeClaimTemplates {
instanceTypes := nodeClaimTemplate.InstanceTypeOptions
// if limits have been applied to the nodepool, ensure we filter instance types to avoid violating those limits
if remaining, ok := s.remainingResources[nodeClaimTemplate.NodePoolName]; ok {
instanceTypes = filterByRemainingResources(instanceTypes, remaining)
... // (validation)
}
nodeClaim := NewNodeClaim(nodeClaimTemplate, s.topology, s.daemonOverhead[nodeClaimTemplate], instanceTypes)
if err := nodeClaim.Add(pod, s.cachedPodData[pod.UID]); err != nil {
... // (error handling)
continue
}
// we will launch this nodeClaim and need to track its maximum possible resource usage against our remaining resources
s.newNodeClaims = append(s.newNodeClaims, nodeClaim)
s.remainingResources[nodeClaimTemplate.NodePoolName] = subtractMax(s.remainingResources[nodeClaimTemplate.NodePoolName], nodeClaim.InstanceTypeOptions)
return nil
}
return errs위의 우선순위에 맞춰 yaml로 작성하는 수많은 규칙을 반영하기 위해, Karpenter 내에서 스케줄링할 노드를 지정해요. 그 과정은 아래 순서대로 진행돼요. (이 코드는 실제 클러스터에 존재하는 노드에 스케줄링하는 상황의 로직이고, NodeClaim에 파드를 추가하는 로직과는 분리되어 작성되어 있어요.)
- 노드와 파드의
taint와toleration의 일치 여부를 파악해요.
// 노드와 파드의 taint-toleration이 일치해야 해요.
if err := scheduling.Taints(n.cachedTaints).ToleratesPod(pod); err != nil {
return err
}2. 노드가 기존에 존재하면, 노드의 volume 제한을 넘지 않는지 확인해요.
// 노드가 기존에 존재하면, 노드의 volume 제한을 넘지 않도록 해요.
volumes, err := scheduling.GetVolumes(ctx, kubeClient, pod)
if err != nil {
return err
}
if err = n.VolumeUsage().ExceedsLimits(volumes); err != nil {
return fmt.Errorf("checking volume usage, %w", err)
}3. 노드의 포트를 중복해서 사용하는지 확인해요.
// 노드의 포트를 중복해서 사용하는지 확인해요.
hostPorts := scheduling.GetHostPorts(pod)
if err = n.HostPortUsage().Conflicts(pod, hostPorts); err != nil {
return fmt.Errorf("checking host port usage, %w", err)
}4. 노드의 리소스 총량이 새로 뜰 파드를 포함한 request 수요를 감당할 수 있는지 확인해요. NodeClaim을 새로 생성한 경우에는 request 총량을 더해서 인스턴스를 새로 생성할 때 활용할 수 있도록 해요.
// 노드의 리소스 총량이 새로 뜰 파드를 포함한 request 수요를 감당할 수 있는지 확인해요.
// NodeClaim을 새로 생성한 경우에는 request 총량을 더해서 인스턴스를 새로 생성할 때 활용할 수 있도록 해요.
requests := resources.Merge(n.requests, podData.Requests)
if !resources.Fits(requests, n.cachedAvailable) {
return fmt.Errorf("exceeds node resources")
}5. nodeAffinity, nodeSelector를 확인해서 노드와 파드의 조건이 부합하는지 확인해요.
// nodeAffinity, nodeSelector를 확인해서 노드와 파드의 조건이 부합하는지 확인해요.
nodeRequirements := scheduling.NewRequirements(n.requirements.Values()...)
if err = nodeRequirements.Compatible(podData.Requirements); err != nil {
return err
}
nodeRequirements.Add(podData.Requirements.Values()...)6. 토폴로지 요건을 확인해요. 이 부분은 nodeAffinity와 topologySpreadConstraint이 공존하는데, 둘 다 이 과정에서 같이 확인하게 돼요. 여기서 preferred 설정이 들어가 있는 affinity는 계산에 포함되지 않게 돼요.
// topology 요건을 확인해요.
topologyRequirements, err := n.topology.AddRequirements(pod, n.cachedTaints, podData.StrictRequirements, nodeRequirements)
if err != nil {
return err
}
if err = nodeRequirements.Compatible(topologyRequirements); err != nil {
return err
}
nodeRequirements.Add(topologyRequirements.Values()...)7. 위 과정을 큐 안에 있는 모든 파드들의 시뮬레이션이 완료될 때까지 반복해요.
Karpenter를 활용한 스케줄링의 장점과 한계
이 과정의 코드를 보게 되면 kube-scheduler의 기본적인 작동 알고리즘과 동일하게 작동하도록 여러 k8s 라이브러리들을 랩핑해서 내부에서 같은 순서로 로직을 돌리고 있어요. 이렇게 구현하면 NodeClaim의 수요를 빠르게 파악할 수 있어, Karpenter의 최대 강점 중 하나인 빠른 프로비저닝을 제공할 수 있어요.
하지만 이 부분이 kube-scheduler와 완전하게 동일하다는 보장은 하긴 어려워요. 이 글을 작성하고 있는 Karpenter v1.1.1 현재, Kubernetes 1.28 버전에서 beta로 전환된 topologySpreadConstraints의 matchLabelKeys 는 스케줄링 과정에서 계산하지 않고 있어요. 저희는 Karpenter를 도입하기 이전, ReplicaSet 별로 skew를 계산하기 위해 matchLabelKey에 pod-template-hash (ReplicaSet 뒤의 난수)를 활용하고 있었는데, Karpenter를 사용하면서 이 기능을 포기해야 했어요.
이 기능은 1년 넘게 Karpenter upstream PR에 올라가 있었다가 1.3.0 버전에서 반영되었어요. 이렇듯 Karpenter는 쿠버네티스의 버전에 따른 변경 사항들을 빠르게 따라오지 못하는 이슈가 있어요. 개인적으로는 kube-scheduler에 접근할 수 있는 인터페이스가 아직 없어서, 더 정확하고 각 버전에 맞는 스케줄링 로직으로 노드를 생성할 수 없다는 게 조금 아쉬웠어요.
2. 커스텀 AMI를 사용할 때 제약사항이 있어요.
당근페이는 보안규정을 준수하는 노드를 효율적으로 제작하고 사용하기 위해 골든 이미지를 만들어요. 골든 이미지란 보안 컴플라이언스를 준수하기 위한 설정들과 접근제어 처리를 한 이미지예요. 추가 설정을 위해 packer + ansible로 베이킹할 필요 없이 준비가 완료된 이미지를 의미하죠. EKS AMI도 이 과정을 거쳐서 생성하고 있는데, 이 이미지들을 활용하기 위해서 EC2NodeClass에 해당 AMI를 사용해야 했어요.
우선 아무 설정 없이 AMI Family (OS)만 설정하면, AWS SSM Parameter Store로 이미지 AMI를 회수해요. (소스코드)
func (a AL2023) resolvePath(architecture, variant, k8sVersion, amiVersion string) string {
name := lo.Ternary(
amiVersion == v1.AliasVersionLatest,
"recommended",
fmt.Sprintf("amazon-eks-node-al2023-%s-%s-%s-%s", architecture, variant, k8sVersion, amiVersion),
)
return fmt.Sprintf("/aws/service/eks/optimized-ami/%s/amazon-linux-2023/%s/%s/%s/image_id", k8sVersion, architecture, variant, name)
}하지만 저희의 커스텀 이미지를 Parameter Store에 보관한 다음 NodeClass 컨트롤러에서 주기적으로 변경 사항을 가져오는 기능은 없었어요. 대신 직접 AMI 지정하거나 AMI를 태그해서 가져올 수 있었는데요. 저희는 실제 프로덕션 환경으로 나가는 계정과 이러한 운영 작업을 위한 계정이 분리되어 있다는 게 문제였어요. AMI를 복사할 때 AMI에 붙은 태그를 타 계정으로 같이 이동시킬 수가 없었죠. 결국 이 과정에 추가적인 리소스를 사용해서 여러 개의 계정에 태그를 동시에 추가하는 별도의 파이프라인을 구성해야 했어요.
3. 작은 노드 위주로 생성해요.
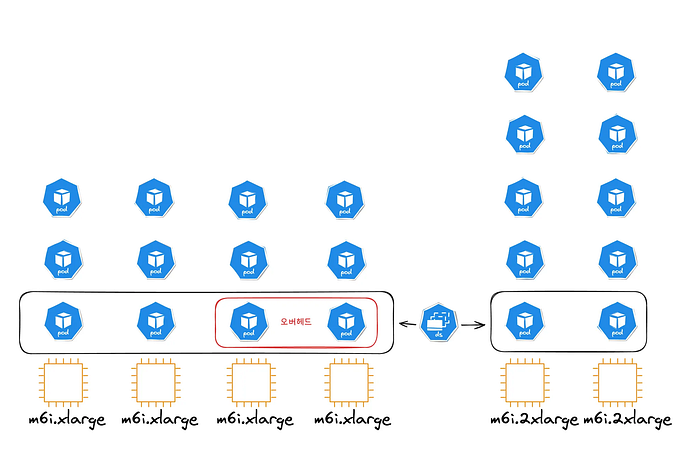
저희는 기존에 2xlarge 노드를 기본으로 ASG를 구성하고 있었어요. 이를 그대로 Karpenter에 올렸더니, 그 이후부터는 xlarge 위주로 노드를 생성하기 시작했어요. Karpenter의 스케줄링 알고리즘에 따르면 현재 파드들의 resource 수요에 맞게 더 촘촘히 노드를 배치할 수 있어 이러한 접근이 유리해요. 그러나 동시에 노드 개수와 비례하여 증가하는 DaemonSet 비용을 무시할 수 없었기 때문에, 팀에서는 저희가 원하는 방향성으로 스케줄링이 되지 않는 이유를 찾아 나섰어요.
그 원인은 저희가 설정한 budget에 있었어요. budget은 NodePool에서 consolidation의 reason 별로 동시에 몇 개의 노드를 삭제할 수 있는지 설정하는 값이에요. 저희는 전반적으로, 그리고 보수적으로 스케줄링하기 위해서 budget을 낮게 잡았고, 그 결과 MultiNodeConsolidation이 발생하지 않은 채 SingleNodeConsolidation만 발생했어요. 결국 하나하나의 노드를 삭제하게 되면서 여러 노드를 하나의 노드로 통합하는 액션이 실제로 작동되지 못했어요.
하지만 budget을 높게 잡아서 disruption의 강도를 높이게 되면, 워크로드들을 너무 공격적으로 이동시키는 것이라고 판단했어요. 그래서 최소 노드 크기를 2xlarge로 설정해서 daemonset으로 인해 발생하게 되는 오버헤드를 줄이려고 했죠.
4. 실제 리소스와 Karpenter에서 인식하는 리소스의 양에 차이가 있어요.
Karpenter 메트릭을 수집하고 대시보드로 관찰하기 시작했는데, 노드들의 실제 리소스 양보다 Karpenter에서 계산한 리소스 양이 적다는 사실을 알게 되었어요. 이에 따라 더 공격적으로 프로비저닝이 발생해 안정성이 떨어졌어요. 게다가 실제 스케줄링과 어긋나는 엣지 케이스들도 발견되었죠.
대시보드에는 EKS AMI와 인스턴스 타입에 따라 제공되는 인스턴스 리소스 크기가 표시되는데요. 정확한 리소스의 차이를 확인하기 위해 노드를 실제로 띄워서 확인해 본 결과, 실제 사용 가능한 리소스의 양과 일치하지 않았어요. 이 값은 OS, kubelet 등 노드를 운용하기 위해 필요한 컴포넌트들이 차지하는 공간인데, 이 공간에 대한 계산을 Karpenter에서 일괄적으로 퍼센티지로 설정해서 발생하는 이슈였어요. (소스코드)
func memory(ctx context.Context, info ec2types.InstanceTypeInfo) *resource.Quantity {
sizeInMib := *info.MemoryInfo.SizeInMiB
...
mem := resources.Quantity(fmt.Sprintf("%dMi", sizeInMib))
// Account for VM overhead in calculation
mem.Sub(resource.MustParse(fmt.Sprintf("%dMi", int64(math.Ceil(float64(mem.Value())*options.FromContext(ctx).VMMemoryOverheadPercent/1024/1024)))))
return mem
}이 부분을 해결하기 위해 가장 먼저 AL2023 EKS AMI를 기준으로 인스턴스를 띄우면 제공되는 메모리양과 free 명령어를 통해 나오는 Available 메모리의 갭을 측정했어요. 이후 저희가 허용하는 인스턴스 중 가장 큰 갭을 기준으로 그 일괄적인 값을 반영해서 사용했어요. 다만, 이 해결법은 엣지 케이스의 빈도를 줄였지만, kube-scheduler에서 인식하는 상태와 Karpenter에서 인식하는 상태가 동일하지 않다는 문제가 있었어요.
1.1.0 버전에서는 한 번 생성된 인스턴스의 실제 리소스 양을 캐싱하도록 패치됐어요. 덕분에 이후 같은 인스턴스 타입을 생성할 때 더 정확한 리소스 값을 반영할 수 있었어요. 특히, 이 업데이트로 인해 Karpenter의 리소스 계산 방식이 개선되면서, 평소 스케줄링의 정합성이 크게 향상되었어요.
5. Node Churn이 발생해요.
Node Churn은 Karpenter에서 consolidation이 한번 발생할 때 여러 개의 노드가 연쇄적으로 disruption되고 새로 생성되는 현상을 말해요. Churn은 휘젓는다는 뜻인데요. Node Churn이 발생하면 국자로 수프를 휘젓듯이 하나의 이벤트로 인해 많은 수의 워커 노드가 한 번에 재배치되기 시작해요.
저희는 처음에 이 문제가 너무 급진적으로 consolidation budget을 잡았기 때문이라고 생각했어요. budget을 10%로 설정한 상태에서 진행했는데 pdb를 겨우 지키는 수준에서 파드들이 계속 노드 사이를 오갔어요. CPU 사용량이 급증하게 되었고, 무려 클러스터 전체 노드 중 약 50%가 순차적으로 지워지고 다시 생성됐어요.
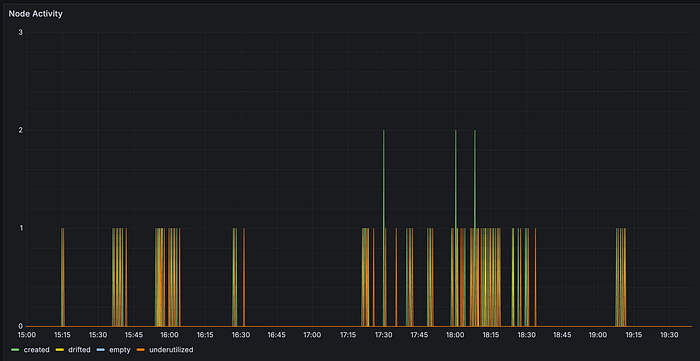
그래서 모든 budget을 1로 설정하고 동시에 consolidation을 진행할 수 없게 하려고 했어요. 이에 따라 작은 노드를 큰 노드로 병합하는 MultiNodeConsolidation을 사용할 수 없게 됐죠. 하지만, 이렇게 해도 Node Churn이 지속적으로 발생했고, 어떨 때는 하루 종일 Churn이 발생하기도 했어요.
이후 메트릭을 확인해 보니 모든 consolidation의 시작 시점은 파드 수요의 변경 시점에 있었어요. Node Churn이 크게 발생할 정도의 본격적인 consolidation은 주로 영업일 낮 시간대였는데요. 새로 배포를 진행하면서 rolling, canary 업데이트를 진행하면서 파드의 수요가 요동치는 거였어요.
이 부분을 개선하고자 이후 개발자들이 배포하는 낮 시간대에는 budget을 1로, 그리고 새벽 시간대에는 budget을 2로 설정했어요. 밤에 budget이 모자라 consolidation이 밀려서 낮에 대규모로 churn이 발생하지 않도록 말이죠. 결과적으로 전체 노드의 10% 내에서 consolidation이 연쇄적으로 발생하는 수준까지 효과적으로 개선했어요.
결과, 앞으로 할 일
Karpenter를 도입하면서 저희는 여러 방면에서 긍정적인 효과를 보게 되었어요. 가장 큰 효과는 비용을 효율적으로 줄였다는 점이죠. 월간 인프라 비용을 약 10,000$ 절감할 수 있었어요. EKS 클러스터 업데이트 과정에서도 워커 노드의 AMI 교체, 노드의 점진적인 업데이트 등을 조금 더 손쉽게 작업할 수 있게 되었어요.
다만 아직 더 개선해야 할 부분도 많아요:
1. 노드 웜업 시간 개선
Karpenter 도입 후 노드가 빠르게 스케일링되면서, 새로 생성된 노드가 워크로드를 정상적으로 처리하기까지 걸리는 초기 웜업 시간 문제가 발생했어요. 이를 해결하기 위해 다음과 같은 방법을 적용했어요:
- 일정 수준의 여유 노드를 유지하는 Overprovisioning 파드를 활용해 모든 가용 영역(Zone)에서 최소한 하나의 노드를 항상 유지하도록 했어요. 이를 통해 갑작스러운 스케일 아웃 시에도 빠르게 대응할 수 있게 됐어요.
- JVM 서비스들에
readinessProbe를 통한 첫 접근을 유도해 클래스들을 미리 로딩함으로써 웜업 시간을 점진적으로 줄여나가고 있어요.
2. 레이턴시 안정화
기존에는 스케일링 없이 진행해서 서비스 레이턴시 증가가 눈에 띄지 않았는데, Karpenter로 인한 Node Churn과 배포가 동시에 일어나 레이턴시가 크게 튀는 경우도 발생했어요. 이를 개선하기 위해 Karpenter에서 제공하는 disruption 방지 어노테이션(karpenter.sh/do-not-disrupt)을 배포 중인 서비스에 자동으로 삽입하는 컨트롤러를 개발 중이에요. 이를 통해 더 안정적이면서도 비용 효율적인 인프라를 조성하기 위해 노력하고 있어요.
3. 스케줄링 정합성 향상
Karpenter와 k8s를 사용하면서 가장 불편함을 느꼈던 스케줄링 흐름 파악을 위해, 현재 Karpenter 스케줄링 시뮬레이터를 개발하고 있어요. 개발이 완료되면 Karpenter와 kube-scheduler의 스케줄링 정합성이 깨졌을 때, 빠르게 원인을 파악하고 문제를 해결할 수 있을 것으로 기대하고 있어요.
당근페이 SRE로 오세요!
당근페이는 전자금융업자로 많은 규제를 받고 있지만 가능한 한 여러 기술에 대해 열린 마음으로 접근하고 있어요. 저희 당근페이 SRE들은 개발자들의 배포 편의성과 인프라의 효율적 운영을 위해서라면, 어떤 기술이라도 심층적으로 분석해요. 또 그 기술이 필요하다고 판단되면 빠르게 도입하죠. 신뢰와 충돌이라는 신념 아래에서 동료들과 다양한 기술을 심도 있게 테스트하고 있어요.
더 효율적이고 아름다운 인프라를 만들어가기 위해 저희와 함께할 분을 찾고 있어요. 많은 관심 부탁드려요!
